Before Transformers, language models were slow. They read text one word at a time, like someone flipping through a book page by page. If you wanted to understand a sentence like "The cat sat on the mat because it was tired," the model had to process each word in order, losing track of earlier words by the time it reached the end. That’s how RNNs and LSTMs worked - and they hit a wall. Training took days. Context got blurry beyond 100 words. Scaling them to handle real human language? Nearly impossible.
Then came the Transformer in 2017. It didn’t just improve things - it broke the mold. Instead of reading word by word, it looked at the whole sentence at once. That single shift unlocked everything we see today: ChatGPT, Gemini, Claude, Llama. All of them run on Transformer architecture. And here’s why that matters.
The Heart of It All: Self-Attention
The secret sauce isn’t fancy math or huge datasets. It’s self-attention. Think of it like a highlighter that dynamically marks connections between words based on meaning, not position.
Take this sentence: "The trophy didn’t fit in the suitcase because it was too big." Who’s too big - the trophy or the suitcase? Humans know it’s the trophy. But old models struggled. Self-attention lets the model say: "'It' relates to 'trophy' because 'fit' and 'big' are connected, and suitcases aren’t usually described as 'too big' in this context." It does this for every word, in every sentence, across thousands of tokens.
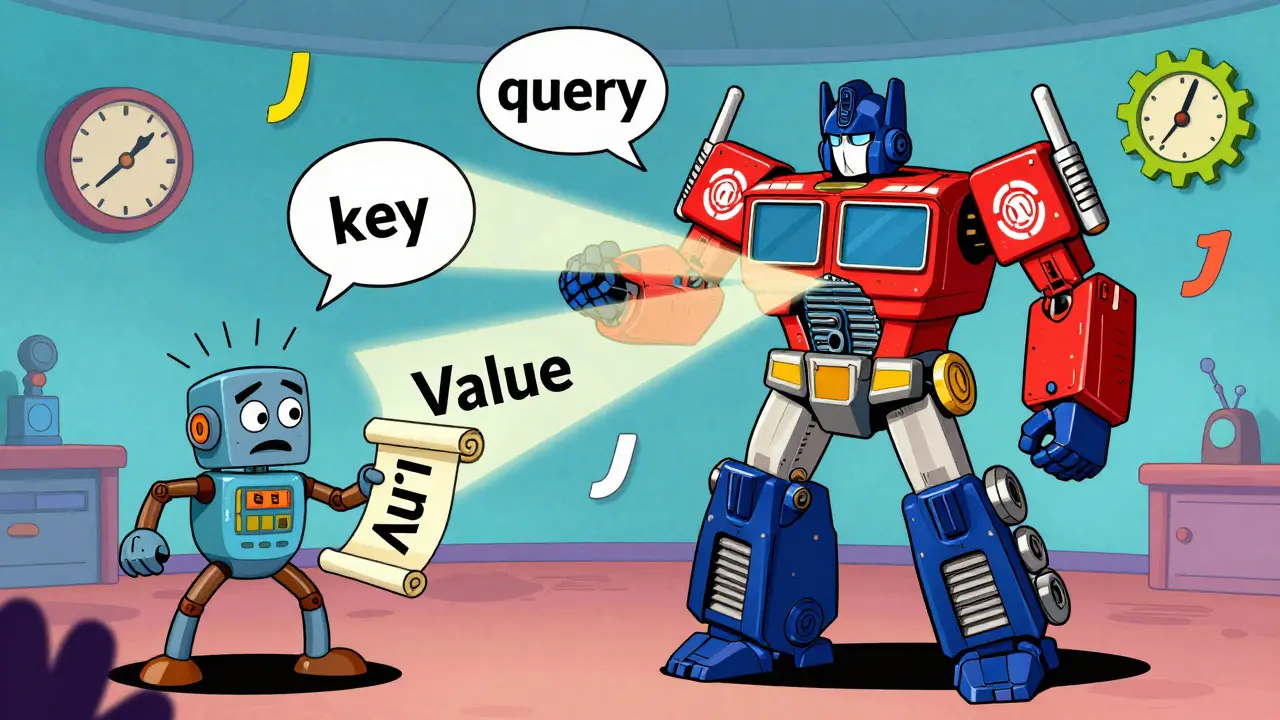
Here’s how it works in practice. Each word gets turned into a vector - a list of numbers. Then, for each word, the model calculates three things: a query, a key, and a value. The query asks: "What am I looking for?" The key answers: "Here’s what I represent." The value is the actual content. The model matches each query to every key, scores the matches, and uses those scores to weight the values. The result? A new representation of each word, shaped by everything else in the sentence.
This isn’t just smart - it’s fast. Because every word is processed at the same time, the model can train on massive datasets in hours, not weeks. That’s why GPT-3 with 175 billion parameters became possible. No RNN could handle that.
Multi-Head Attention: Seeing Multiple Perspectives
Self-attention alone is powerful. But Transformers go further with multi-head attention. Imagine eight different people reading the same sentence, each focusing on something different: one on grammar, one on emotion, one on names, one on cause and effect. Then they all share notes.
In GPT-2, there are 12 of these "heads." In GPT-3, up to 96. Each head learns its own pattern - some catch synonyms, others track pronouns, others spot sarcasm. The model combines all their insights into one richer understanding. That’s why Transformers don’t just mimic language - they start to grasp nuance.
Without multi-head attention, models would oversimplify. They’d treat every word relation the same. But language is messy. "Bank" can mean money or a river. "Run" can mean jog, operate, or manage. Multi-head attention lets the model hold all those meanings at once - and pick the right one based on context.
Positional Encoding: Knowing Order Without Sequences
Here’s a problem: if you process all words at once, how do you know which one comes first? A sentence like "Dog bites man" means something totally different from "Man bites dog." RNNs knew order because they processed words one after another. Transformers don’t have that built-in.
So they use positional encodings. These are fixed mathematical patterns added to each word’s vector that tell the model its position in the sequence. Think of them like tiny GPS tags on every word. The pattern is designed so the model can learn relative distances - word 5 is 3 steps ahead of word 2 - even if it’s never seen that exact sentence before.
This trick is simple, but brilliant. It lets Transformers handle any length of text without retraining. GPT-2 handles up to 1,024 tokens. GPT-4 Turbo handles 128,000. The positional encoding doesn’t change - it just scales.

Encoder vs. Decoder: Two Flavors of Transformers
Not all Transformers are built the same. There are three main types, each suited for different jobs.
- Encoder-only (like BERT): Reads text and understands it. Used for tasks like answering questions, classifying sentiment, or tagging entities. BERT’s strength? It looks at both sides of a word - what came before and after. That’s why it’s great at understanding.
- Decoder-only (like GPT): Generates text one word at a time. It sees only what’s come before - no peeking ahead. That’s how it writes essays, replies to messages, or codes. GPT-3.5, GPT-4, Llama 3 - all decoder-only. They’re autoregressive: predict the next word, then use that to predict the next, and so on.
- Encoder-decoder (like T5): Does both. Reads input, then generates output. Used for translation, summarization, or question answering where you need to transform one thing into another. T5 treats everything as a text-to-text task: "Summarize: [input]" → "[summary]".
Today, decoder-only models dominate because they’re simpler to scale and better at open-ended generation. That’s why most public-facing AI tools - from chatbots to content writers - use them.
Why Transformers Scale So Well
Scaling a model isn’t just about adding more layers or parameters. It’s about making training efficient. Transformers win here because of parallelization.
With RNNs, you can’t compute word 5 until word 4 is done. It’s a chain. Transformers? Every word can be computed at the same time. That’s why Google trained GPT-3 on thousands of GPUs and finished in days, not months. It’s also why models exploded from millions to hundreds of billions of parameters.
That scaling isn’t just about size - it’s about quality. Bigger models don’t just memorize more. They start to reason. GPT-3 got 43.9% right on math problems. Minerva, a fine-tuned Transformer, got 78.5%. Why? More parameters let the model build internal representations of logic, patterns, and structure - not just word patterns.
And it’s not just big companies doing this. Open-source models like Llama 3 (8 billion to 70 billion parameters) are now competitive with proprietary ones. Developers can download, fine-tune, and run them locally. That’s why enterprise adoption is growing fast - 83% of companies using LLMs now prefer open models for control and privacy.
Where Transformers Still Struggle
Transformers aren’t magic. They have limits.
First, computational cost. Self-attention scales quadratically. A 1,000-word input needs 1 million attention calculations. That’s why most models cap context at 4,096 or 32,000 tokens. Anthropic’s Claude 2 pushed to 100,000 - but it cost 10x more in compute. Stanford’s FlashAttention algorithm cut that cost by 3x, but it’s still expensive.
Second, reasoning. Transformers predict the next word based on patterns. They don’t think like humans. Give them a math word problem? They’ll guess the answer from similar problems they’ve seen. That’s why they fail on logic puzzles or code that requires step-by-step deduction - unless you fine-tune them heavily. Minerva succeeded because it was trained on 100,000 math problems with step-by-step solutions.
Third, hallucinations. Because they’re trained on vast amounts of internet text, they often generate confident-sounding nonsense. A 2023 study found that even GPT-4 hallucinates facts in 20% of medical responses. That’s why companies using them for customer service or legal work still need human oversight.
What’s Next? Beyond Transformers
Transformers dominate now - 98.7% of top NLP papers use them. But they’re not the end.
Researchers are already exploring alternatives. State Space Models (SSMs) can handle long contexts with linear, not quadratic, complexity. Google’s Gemini 1.5 uses a "Mixture-of-Experts" system - only activating a fraction of its 1.5 trillion parameters per task. Mistral AI’s 7B model uses sliding window attention to cut memory use by 80%.
Hybrid models are coming too. Some combine Transformers with symbolic reasoning engines. Others use retrieval-augmented generation - pulling in real-time data before answering. OpenAI’s GPT-4 Turbo does this to answer questions about current events.
But for now, Transformers are the foundation. They’re the reason you can ask an AI to explain quantum physics in plain English - and get a clear answer. They’re why customer service bots now resolve issues in seconds instead of days. And they’re why businesses are spending billions to build, fine-tune, and deploy them.
Real-World Impact: What This Means for You
You don’t need to build a Transformer to benefit from one.
A Fortune 500 company cut customer response time from 12 hours to 45 seconds using a fine-tuned BERT model. They processed 2.3 million queries a month with 92.7% accuracy. That’s not science fiction - it’s real.
For developers: Tools like Hugging Face make it easy to fine-tune models. You can train a custom chatbot on your internal docs in a weekend. LoRA adapters let you do it on a single 24GB GPU - no need for a data center.
For businesses: If you’re handling customer support, content creation, or data extraction, Transformers are already cheaper and faster than hiring people. The cost of running a 7B model is now under $0.01 per 1,000 words.
For everyone: The barrier to entry is falling. You can run Llama 3 on your laptop. You can use Claude for free. You can build an AI assistant that knows your company’s policies. The tools are here. The models are proven. The only question left is: what will you do with them?
What makes Transformers better than older models like LSTMs?
Transformers process all words in a sentence at the same time using self-attention, while LSTMs read one word at a time. This lets Transformers train faster, handle longer texts, and understand context better. LSTMs struggled with long-range dependencies - a word at the end of a paragraph often lost its connection to the start. Transformers don’t have that problem.
Do I need a supercomputer to use a Transformer model?
No. While training massive models like GPT-4 needs hundreds of high-end GPUs, using or fine-tuning smaller ones (like BERT or Llama 3) is doable on consumer hardware. With techniques like LoRA and quantization, you can run a 7B-parameter model on a single 24GB GPU. Many developers do this for personal projects or small business apps.
Why do Transformer models sometimes make things up?
They’re trained to predict the next likely word, not to verify facts. If they’ve seen a similar pattern in training data - like "Einstein invented the light bulb" - they’ll generate it confidently, even if it’s wrong. This is called hallucination. To reduce it, you can use retrieval-augmented systems that pull answers from trusted sources, or fine-tune on verified data.
Are Transformers the only option for large language models today?
Right now, yes - over 98% of top-performing LLMs use Transformers. But alternatives are emerging. State Space Models (SSMs) are faster for very long texts and use less memory. Hybrid models combining Transformers with symbolic logic are being tested. Still, no architecture has matched Transformers’ versatility across tasks like translation, summarization, coding, and reasoning - yet.
How do I get started with Transformer models?
Start with Hugging Face. They offer free, pre-trained models and step-by-step tutorials for fine-tuning. Pick a task - like sentiment analysis or chatbot replies - and use their "Transformers" library in Python. You can train a basic model on your laptop in a few hours. For more power, use cloud services like Google Colab or AWS. Most beginners skip training from scratch and just fine-tune existing models.


It's wild how self-attention just *clicks* when you think about it - like your brain doesn't read word by word either. You don't need to finish a sentence to know if it's sarcastic or tragic. That's the magic. Transformers mimic that human intuition. We've been trying to force machines to think like computers, but the real breakthrough was letting them perceive like people. No wonder they're suddenly good at poetry, jokes, even coding. It's not about more data - it's about how the data talks to itself.
i read this whole thing and honestly i think its just hype like always u know like everyone says transformer this transformer that but like whats the diffrence really i mean i asked my phone to write me a poem and it did but then it said the moon is made of cheese and i was like lol but also wait why did it say that like why cant it just know stuff for real not just guess the next word like its some kinda fancy autocomplete with a ego
They don't want you to know this but Transformers were reverse-engineered from classified military tech in the 90s. The real reason they scale so well? Because they're built on neural nets originally designed to predict enemy troop movements - now they're predicting your grocery list. That's why they hallucinate so much - they're still trying to map civilian chatter onto battlefield logic. And don't get me started on positional encoding - that's just a backdoor for surveillance. They know where every word sits. They know *when* you typed it. This isn't AI. It's a listening device wearing a smile.
so i read the part about multi-head attention and honestly i zoned out after the first paragraph like i get it its like 8 people looking at the same thing but why do we need 96 heads?? like is gpt-4 just a bunch of overworked interns screaming at each other in a google doc? also the whole thing about scaling is cool but i tried running llama on my laptop and it froze my whole system so yeah cool tech but also why does it take 30gb of ram to tell me what 2+2 is
I love how this post breaks down something so complex into something you can actually feel. I used to think AI was just magic, but now I see it’s more like a really good listener - it doesn’t understand the world the way we do, but it notices patterns we miss. That’s not scary. That’s helpful. And the fact that someone with a 24GB GPU can now build something meaningful? That’s the future. Not in some distant lab. Right here. Right now. Keep building.
Thank you for this clear and thoughtful explanation. It is important to recognize that while the technology is advanced, the underlying principle is simple: context matters. The human mind thrives on context, and now machines are beginning to do the same. This is not a replacement for human judgment, but a tool that, when used with care, can support understanding. I believe that with patience and responsibility, we can guide this progress toward greater good.