
Remember the last time you searched for something online and got a list of results that technically contained your keywords but completely missed the point? You type in "best way to fix a leaky faucet," and instead of step-by-step repair guides, you get ads for plumber insurance or articles about water conservation. It’s frustrating because the engine saw the words, but it didn’t understand what you actually needed.
This gap between keyword matching and true understanding is exactly where Semantic Search powered by Large Language Models (LLMs) changes the game. We are moving past the era of simple text lookup into an age of intelligent answer engines. By leveraging the massive scale of transformer architectures, these systems don't just scan for character strings; they comprehend context, intent, and the subtle relationships between concepts. For engineers and product teams building search features in 2026, this isn't just a nice-to-have-it's the new baseline for user experience.
The Shift from Keywords to Vector Embeddings
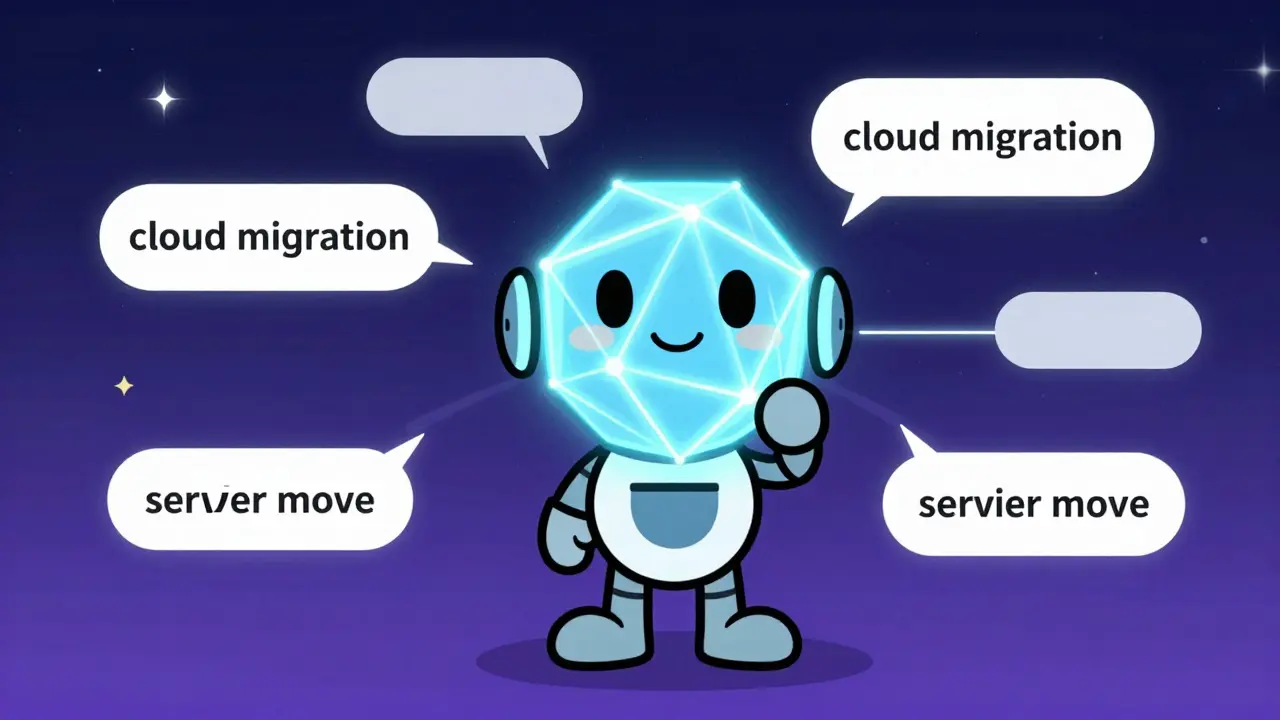
To understand why traditional search fails, you have to look at how it works under the hood. Legacy systems rely on inverted indexes. They map every word in their database to the documents containing that word. If you search for "cloud migration cost," the system looks for those three specific terms. If a document says "budgeting for a cloud transition," the legacy engine sees zero overlap. It returns nothing relevant, even though the meaning is identical.
Semantic search solves this using Vector Embeddings numerical representations of text that capture semantic meaning. An embedding model converts text into a long list of numbers-a vector-where each number represents a different aspect of meaning. Texts with similar meanings end up close together in this multi-dimensional space. When you search, you aren't matching words; you're finding vectors that are mathematically close to your query vector.
Here is where Large Language Models make a huge difference. Older embedding models were limited by their size and training data. Modern LLMs, trained on billions of parameters across vast internet corpora, generate embeddings that are far more nuanced. They understand that "server migration" and "moving databases to the cloud" occupy nearly the same spot in the semantic landscape. This allows search systems to handle ambiguity, slang, and complex phrasing without breaking a sweat.
The Three-Stage Architecture of Modern Semantic Search
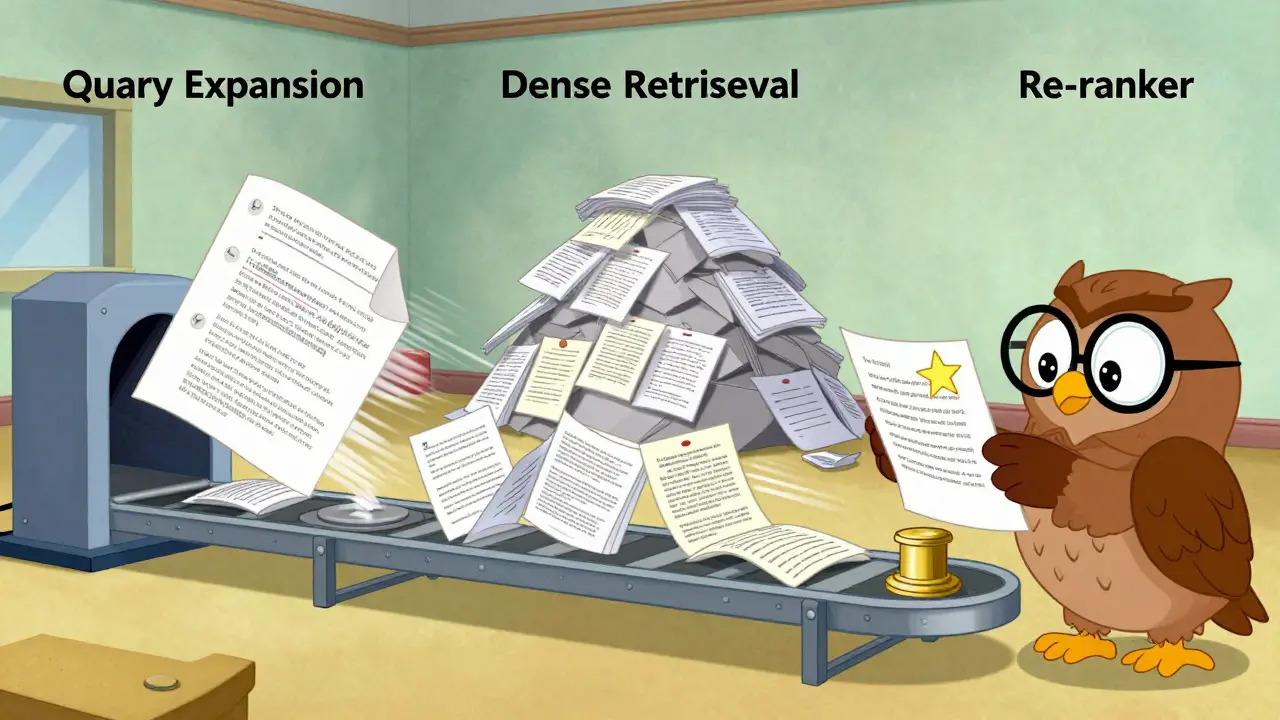
Building a robust semantic search system isn't just about plugging in an LLM. It requires a structured pipeline that balances speed, recall, and precision. Most high-performing systems today use a three-stage approach: Query Expansion, Dense Retrieval, and Re-ranking.
- Query Expansion: Users often write short, vague queries. An LLM expands these into multiple, more detailed variations before the search begins. If you type "Oracle Cloud," the system might automatically generate parallel searches for "OCI pricing vs AWS," "Oracle Cloud Infrastructure benefits," and "migrating to OCI." This increases recall, ensuring you don't miss relevant documents just because the user didn't phrase it perfectly.
- Dense Retrieval (Initial Search): The system uses the expanded queries to perform a fast vector similarity search against your database. This stage prioritizes speed. It pulls back a broad set of potentially relevant candidates-maybe the top 100 documents-from millions of options. It’s not perfect yet, but it’s fast and covers a wide net.
- Re-ranking: This is where the real intelligence kicks in. A specialized cross-encoder model or LLM takes the top 100 candidates and analyzes them deeply alongside the original query. It doesn't just look at vector proximity; it reads the content. It understands that one document mentions "cloud migration" once as a footnote, while another discusses "migration strategies" in depth. The re-ranker corrects the initial scores, pushing the most contextually relevant results to the top. This ensures precision.
This combination gives you the best of both worlds: the speed of vector search and the accuracy of deep linguistic analysis.
Why Re-Ranking Is Your Fastest Path to Value
If you are managing an existing search infrastructure, overhauling everything to use dense retrieval can be expensive and slow. You might wonder if there’s a quicker win. There is: Re-ranking the process of re-evaluating search results using advanced models.
Research and practical implementation show that injecting LLM intelligence via re-ranking is often the fastest way to improve search quality without rebuilding your entire stack. You keep your current keyword-based or basic vector search for the initial fetch. Then, you send those results through an LLM-powered re-ranker. The model evaluates the relevance of each result based on complete contextual understanding rather than just keyword density.
For example, in a customer support knowledge base, a user asks about "refund policy for damaged goods." A keyword search might return the general refund page first because it contains the word "refund" frequently. But a re-ranker will recognize that the section specifically titled "Damaged Items Protocol" is the actual answer, even if it uses fewer exact matches. It fixes the ordering problem instantly.
Technical Foundations: Pre-Training and Masked Language Modeling
How do these models actually learn to understand meaning? It comes down to their pre-training process. Models like MPNet or BERT variants use a technique called Masked Language Modeling a training method where the model predicts hidden words in a sentence. During training, random words in a sentence are hidden, and the model must predict them based on the surrounding context.
This forces the model to develop a two-way understanding of language. To predict the missing word, it has to analyze grammar, semantics, and world knowledge from both the left and right sides of the token. Over billions of iterations, this creates a deep internal representation of how concepts relate to each other. When you later use this model for search, it’s not guessing; it’s applying a sophisticated statistical understanding of human language that was built during that pre-training phase.
Real-World Applications Beyond General Search
Semantic search with LLMs isn't limited to Google-style web searches. It’s transforming several specific domains:
- E-commerce Product Discovery: Shoppers rarely know the exact SKU or technical name of what they want. They describe needs: "comfortable shoes for standing all day." Semantic search identifies the intent and returns products tagged with "orthopedic support" or "all-day comfort," even if those exact phrases aren't in the user's query.
- Document Management & Legal Tech: In digital libraries or legal databases, finding a contract clause about "indemnification" shouldn't require knowing the exact legal terminology. Semantic search retrieves documents based on conceptual similarity, helping lawyers find precedents faster.
- Enterprise Knowledge Bases: Companies have terabytes of internal documentation. Employees waste hours searching for answers. LLM-enhanced search synthesizes information from multiple documents to provide direct, summarized answers, turning static wikis into active assistant tools.
Challenges and Implementation Pitfalls
While the technology is powerful, it’s not magic. Implementing semantic search at scale comes with challenges. First, there’s the data requirement. Training or fine-tuning deep learning models requires large amounts of high-quality text data. If your domain is highly niche, generic LLM embeddings might not perform well out of the box. You may need to fine-tune the model on your specific vocabulary to ensure it understands industry jargon.
Second, there’s the issue of latency. While vector search is fast, adding a re-ranking step introduces computational overhead. You have to balance the depth of analysis with the speed of response. Using efficient indexing methods, such as in-memory indexing, can help mitigate this, but architecture decisions matter. You also need to guard against hallucinations if you’re using the LLM to generate direct answers. Always ground the generated responses in the retrieved documents to maintain accuracy.
What is the difference between keyword search and semantic search?
Keyword search matches exact characters or stems from your query to the text in documents. Semantic search uses vector embeddings to understand the meaning and intent behind the query, returning results that are conceptually similar even if they don't share exact words.
Do I need to rebuild my entire search engine to use LLMs?
No. The fastest way to integrate LLM capabilities is often through re-ranking. You can keep your existing search infrastructure for initial retrieval and add an LLM-based re-ranker to refine the order of results before showing them to the user.
What are vector embeddings?
Vector embeddings are numerical representations of text. They convert words or sentences into lists of numbers where similar meanings are located close together in mathematical space, allowing computers to measure semantic similarity efficiently.
How does query expansion improve search results?
Query expansion uses an LLM to generate multiple related search queries from a single user input. This increases recall by casting a wider net, ensuring that relevant documents are found even if the user's original phrasing was too narrow or ambiguous.
Is semantic search slower than traditional search?
It can be, depending on implementation. Vector search is very fast, but adding steps like LLM-based re-ranking or query expansion adds latency. However, optimized architectures using in-memory indexing and efficient models can deliver results in milliseconds, making the trade-off worth it for improved relevance.


