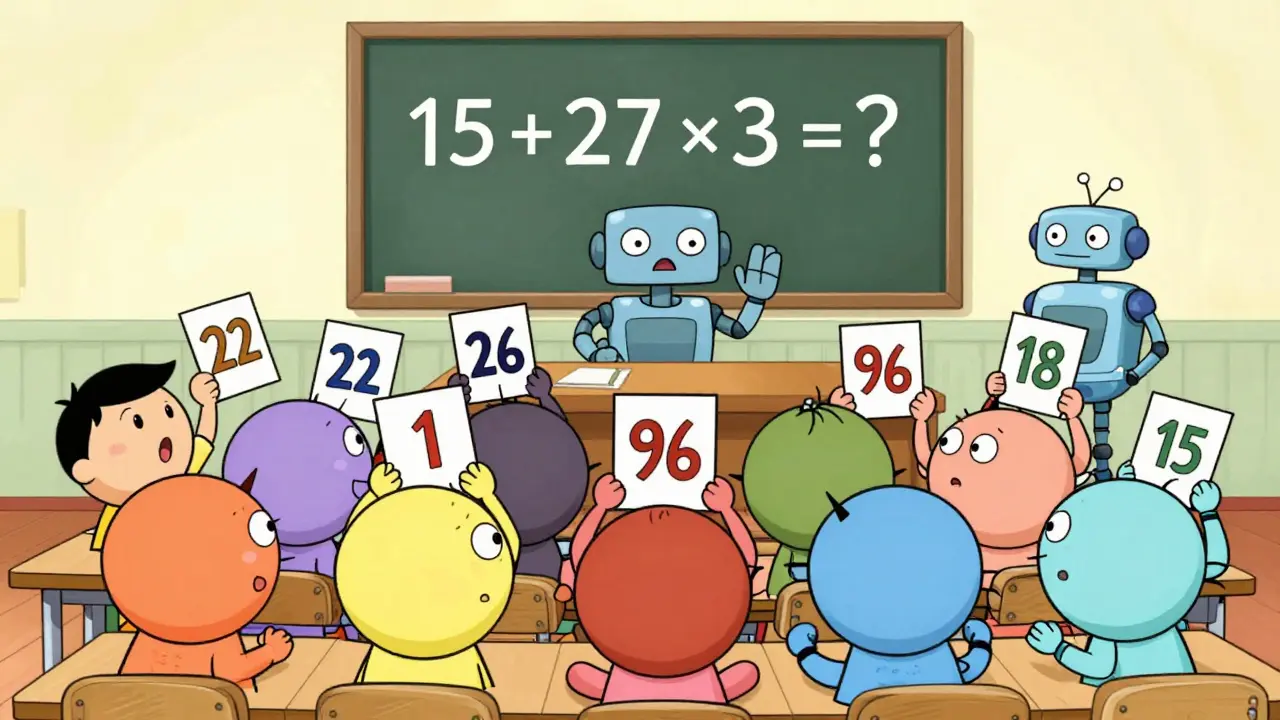
Imagine asking a language model to solve a math problem - and getting a different answer every time. Not because it’s confused, but because it’s too creative. That’s the problem self-consistency prompting solves. Instead of trusting one guess, it asks the model to think through the same question 10, 20, or even 30 times, then picks the answer that shows up most often. It’s like polling a classroom: if 22 out of 30 students say the answer is 42, it’s probably right.
How Self-Consistency Prompting Actually Works
Self-consistency prompting builds on Chain-of-Thought (CoT) prompting, where you ask the model to show its work step by step. But instead of stopping after one try, you run the same prompt multiple times with slight variations in how the model generates its response. This isn’t random noise - it’s controlled diversity. Here’s the exact process:- Start with a clear prompt that includes an example of step-by-step reasoning (like solving 15 + 27 × 3).
- Use stochastic sampling - not greedy decoding - to generate multiple outputs. That means setting the temperature between 0.5 and 1.0. Lower values (0.5) make responses more focused; higher ones (1.0) let the model explore wilder paths.
- Collect all the final answers from each run.
- Use majority voting: pick the answer that appears most frequently.
Why Majority Voting Beats Single Guesses
Large language models aren’t perfect. They make mistakes, but they don’t make the same mistakes every time. A wrong answer usually comes from a flawed logic chain - maybe a misapplied formula or a misunderstood word. But the right answer? It can be reached through multiple valid paths. Think of it like solving a maze. One person takes the left turn and hits a dead end. Another takes the right and gets stuck too. But five others all take the middle path and reach the exit. That middle path isn’t luck - it’s the correct route. This is why self-consistency works best on tasks with clear, verifiable answers: math problems, logic puzzles, medical diagnosis based on lab results, or legal code interpretation. If there’s only one right answer, the crowd usually gets it right. In contrast, creative writing, open-ended brainstorming, or opinion-based questions don’t benefit. There’s no “correct” ending to a story. Voting among 20 different endings doesn’t produce a better one - it just picks the most common. And that’s not creativity. That’s conformity.Real-World Performance Numbers
The data doesn’t lie. Here’s what happens when you scale up the number of reasoning paths:- 3 paths at temperature 0.5: 59.2% accuracy on GSM8K
- 10 paths at temperature 0.7: 63.1% accuracy
- 15 paths at temperature 1.0: 66.5% accuracy
- 30 paths at temperature 1.0: 68% accuracy
When It Fails - And Why
Self-consistency isn’t magic. It has blind spots. In legal reasoning tasks, researchers found that when 70% of the model’s reasoning paths shared the same flawed interpretation of a statute, majority voting picked the wrong answer - consistently. The model wasn’t guessing wrong randomly. It was all wrong together. That’s called collective hallucination. And in open-ended tasks? It’s useless. If you ask for a poem about loss, and get 20 different poems, voting doesn’t find the best one - it just finds the most popular. But popularity doesn’t equal quality. A 2025 study from Stanford HAI showed self-consistency perpetuated errors in 22% of legal reasoning cases where the majority of paths contained the same logical flaw. That’s not improvement - that’s amplification. This is why human oversight still matters. Self-consistency doesn’t replace judgment. It sharpens it.How to Implement It Right
If you’re trying this yourself, here’s what works:- Start with 5-10 paths. Don’t jump to 30 unless you need it.
- Use temperature 0.7 for balanced diversity. Lower (0.5) if the task is precise (like medical QA). Higher (1.0) if the problem has multiple valid approaches (like math word problems).
- Always log the full reasoning paths - not just the final answer. You’ll need them to debug when things go wrong.
- Handle ties by randomly selecting one of the tied answers. Don’t overthink it.
- Test on your own data. What works on GSM8K might not work on your customer support logs.

What’s Next? The Rise of Hybrid Systems
Self-consistency is becoming a building block, not a final solution. In January 2026, Amazon Bedrock introduced adaptive path counting: it starts with 5 paths. If the answers don’t agree, it adds more - up to 30 - only when needed. That cuts compute costs by 42% without losing accuracy. Anthropic’s Claude 3.5 now has a built-inreasoning_consistency parameter. Set it to 7, and the model automatically picks the right temperature and path count for your task. No more guessing.
Even GPT-5 and Claude 4 now bake self-consistency into their architecture. You don’t have to prompt it - the model does it internally.
That’s the future: not asking the model to vote, but designing it so it votes on its own.
Who’s Using This Right Now?
You won’t find self-consistency in your Instagram feed. But you’ll find it in places where accuracy saves lives or money:- Quantitative trading firms: 83% use it to validate financial predictions from AI models.
- Healthcare AI: 67% of diagnostic systems use it to cross-check lab result interpretations.
- Legal tech startups: They use it to flag inconsistent interpretations of contracts - but always with a lawyer reviewing the output.
Final Thought: Consensus Isn’t Truth
Self-consistency is powerful because it turns randomness into reliability. But it’s not infallible. It doesn’t make models smarter. It just makes their mistakes less random. Use it for verifiable tasks. Avoid it for creative ones. Always check the reasoning paths. And never trust a majority vote if the crowd is wrong for the same reason. The best AI systems don’t just vote. They question the vote.What’s the difference between self-consistency prompting and standard Chain-of-Thought?
Standard Chain-of-Thought generates one reasoning path and stops. Self-consistency generates multiple paths using stochastic sampling, then picks the most common final answer through majority voting. This reduces random errors and improves accuracy on tasks with clear right answers.
Does self-consistency prompting work for creative writing?
No. Creative writing has no single correct answer. Voting among 20 different poems won’t find the best one - it’ll just find the most common. Self-consistency works only when there’s a verifiable outcome, like a math solution or medical diagnosis.
How many reasoning paths should I use?
Start with 5-10 paths. For simple tasks like arithmetic, 5-10 is enough. For complex problems like multi-step math or medical QA, use 15-20. Beyond 30, accuracy gains are minimal, but compute costs keep rising. Use adaptive systems if available.
What temperature setting is best for self-consistency?
Temperature 0.7 is a good starting point. Use 0.5 for precise tasks (like legal code interpretation) where you want focused reasoning. Use 1.0 for tasks with multiple valid approaches (like math word problems) to encourage diversity. Higher temperatures need more paths to compensate for randomness.
Is self-consistency prompting expensive?
Yes. Generating 30 paths uses roughly 30 times more compute than one. That can spike costs dramatically for high-volume applications. But platforms like Amazon Bedrock now offer batch inference and adaptive path counting, which can reduce costs by up to 42% while keeping accuracy high.
Can self-consistency make mistakes worse?
Yes. If most reasoning paths share the same flawed logic - like misinterpreting a law or misapplying a formula - majority voting will pick the wrong answer confidently. This is called collective hallucination. Always review the reasoning paths, not just the final vote.
Is self-consistency still relevant in 2026?
Yes - but as a component, not a standalone method. Newer models like GPT-5 and Claude 3.5 now include self-consistency internally. The future isn’t prompting it manually - it’s trusting models that do it automatically. But the core idea - using consensus to improve reliability - is here to stay.



Oh sweet mercy, this is the most beautiful thing I’ve read all week - like watching a symphony of neurons finally stop screaming and start singing in harmony. Self-consistency isn’t just a trick; it’s the AI equivalent of a Zen master meditating on a math problem until the universe whispers the answer. 30 paths? 1.0 temperature? That’s not engineering - that’s alchemy. And yes, I’m crying a little. This is the future, and it’s gorgeous.
Okay but WHY does no one talk about how this makes AI feel like a cult? 22 out of 30 say 42? What if they’re all wrong because the question was phrased wrong?!! I’m not saying it doesn’t work - I’m saying it’s terrifying how easily we delegate truth to a majority vote from a machine that doesn’t even know what ‘truth’ means. I’m not okay. I need a nap.
You people are missing the point. This isn’t about voting. It’s about error distribution. The model isn’t guessing - it’s exploring the solution space. And yes, the numbers are real: GSM8K jumped from 51.7% to 68%. That’s not ‘magic’ - it’s statistics. And before you start crying about ‘collective hallucination,’ read the Stanford paper again. It’s not about the vote - it’s about logging the paths. If you’re not inspecting the reasoning chains, you’re not using it right. You’re just gambling with GPT.
Bro. I tried this on my startup’s customer support bot. First try? Temperature 1.0, 30 paths. Got 17 different answers for ‘how do I reset my password?’ One said ‘drink coffee and cry.’ Another said ‘delete your soul.’ I was sobbing in my cubicle. Then I dropped it to 0.7 and 10 paths. Now it works. Not perfect. But human enough. I’m not a genius. I’m just tired. And this? This saved my job.
Let me just say, as someone who edits technical documents for a living, this entire post is grammatically impeccable - except for one thing: you wrote ‘it’s’ when you meant ‘its’ in the third paragraph. No, I’m not kidding. It’s ‘its’ because it’s possessive. And also, you have a dangling modifier in the section about legal reasoning. And the Oxford comma? Missing in three places. I’m not mad. I’m just disappointed. Also - why are you using ‘path’ instead of ‘iteration’? Path implies direction. Iteration implies repetition. You’re confusing the reader. Fix this. Please. For the love of grammar.
Okay but imagine if we applied this to dating apps 🤔 Like, ‘Hey AI, generate 20 intros for my profile’ - then vote on the best one? The most popular one? ‘I like long walks on the beach and existential dread’ wins because 12 people liked it? 😭 We’re already living in the simulation. And now AI is voting on our souls? I’m not scared. I’m just… emotionally prepared. Also, I’m using this for my poetry. Not for the answer - for the chaos. It’s beautiful. ✨
Consensus isn’t truth. But neither is individual genius. What if the ‘correct’ answer is the one no one thought of? What if the 8% who got it right were the only ones who understood the question? What if truth is a minority… and we’re all just voting for comfort? 🤷♀️ I’m not anti-technology. I’m pro-silence. And silence doesn’t vote.
Look. I’ve been in AI for 10 years. I’ve seen fads come and go. This one? It’s staying. Why? Because it works. Not because it’s elegant. Not because it’s poetic. Because when your model is making $500k in bad trades because it thought ‘30% interest’ meant ‘30% APR,’ you don’t care about philosophy - you care about 68% accuracy vs 51%. So yeah, I use it. I log the paths. I watch for collective hallucinations. And I don’t let it near my creative writing prompts. Simple. Effective. Done.