Large language models (LLMs) aren’t getting smarter just because they’re bigger. The real breakthroughs aren’t in adding more parameters-they’re in how you feed them data. If you’ve been following LLM progress, you’ve heard about models with hundreds of billions of parameters. But here’s the secret: the next leap in performance isn’t about size. It’s about sequence and mix.
Why Random Data Isn’t Enough Anymore
For years, training LLMs meant throwing trillions of random tokens at a model and hoping it learned something useful. It worked-sort of. Models got better, but the returns were fading. Each doubling of compute gave smaller gains. That’s the classic scaling law problem: diminishing returns. Enter curriculum learning. It’s not new. In early neural networks, teachers used to start with simple problems before moving to hard ones. But applying that to LLMs? That’s different. You can’t just sort data by word count. You need to understand what the model is learning and when it’s ready for more. MIT-IBM Watson AI Lab’s 2025 research found that simply reordering data using a smart curriculum could boost performance by up to 15%-without changing a single parameter. That’s like getting a 1.15x bigger model for free.The Three Pillars of a Smart Data Mixture
NVIDIA’s 2025 framework broke down effective data mixtures into three measurable dimensions:- Breadth: How many domains does the data cover? A model trained only on Wikipedia will struggle with legal documents, code, or medical journals.
- Depth: How complex is the content within each domain? Simple sentences vs. multi-step reasoning problems.
- Freshness: How recent is the information? Tech terms change fast. A model using 2020 data won’t know what “RAG” or “MoE” mean in 2026.
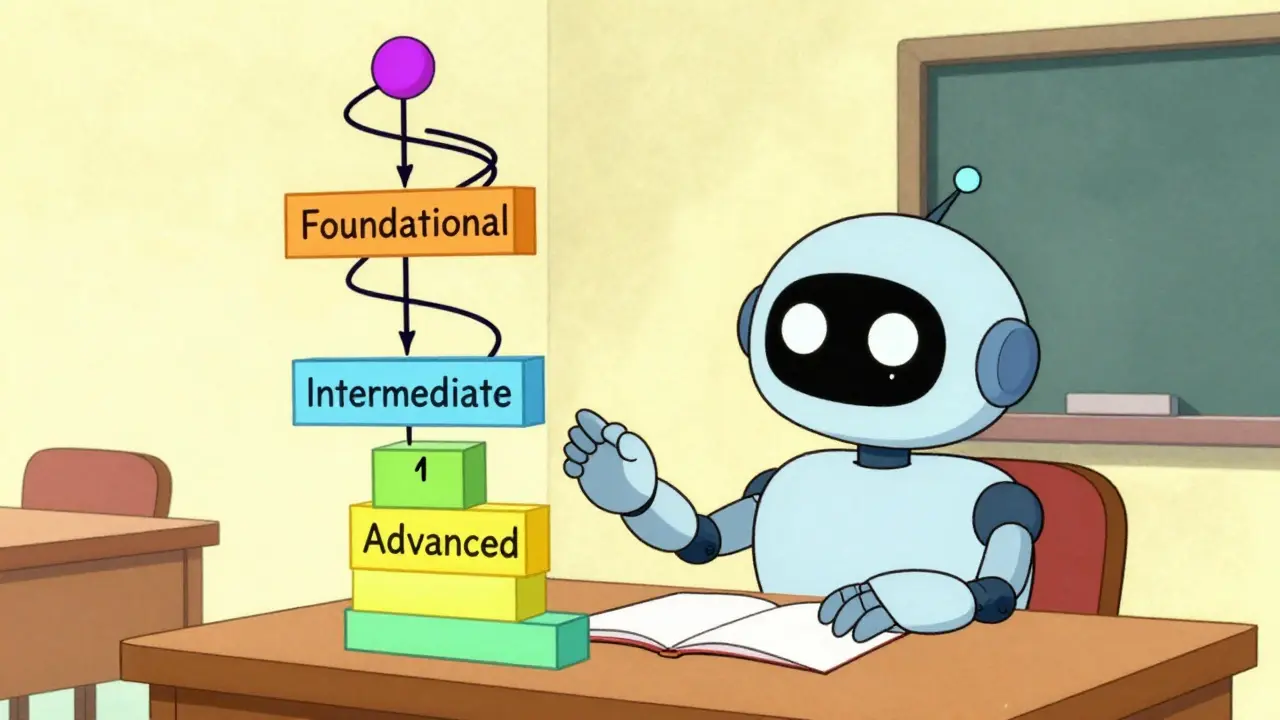
- 60% foundational: basic grammar, common facts, everyday language
- 30% intermediate: specialized knowledge, logical reasoning, domain-specific jargon
- 10% advanced: abstract concepts, multi-hop inference, cross-domain synthesis
How Much Does It Cost to Get Smart?
You might think this sounds great-until you realize how hard it is to pull off. Tagging data for complexity, domain, and accuracy isn’t easy. It requires tools that analyze syntax, concept density, and factual correctness against knowledge bases. Meta’s team spent 37% more time preprocessing data for Llama 3.1. That’s a lot of engineering hours. And it’s expensive. Meta’s internal numbers show an 8-12% increase in training overhead just for data preparation. But here’s the math: if you cut total training time by 18.7% because your model learns faster, that overhead pays for itself. Google’s Gemma 3 showed something surprising: you don’t need a fancy system. Just sorting data by basic difficulty (short sentences → long paragraphs → reasoning chains) gave them 85% of the benefits of a full multi-dimensional curriculum-with only 15% of the effort. That’s the sweet spot for most teams. Start simple. Sort by length and complexity. Use open-source tools like DataComp (released by MIT-IBM in August 2025), which already has 10 trillion tokens pre-tagged. You can cut setup time by 40%.
Where It Falls Apart
Curriculum learning isn’t a magic bullet. It breaks in surprising ways. On Reddit, a user named “lang_engineer” tried applying a curriculum to a multilingual model. It worked great for English. But for Swahili, Urdu, and other low-resource languages, performance dropped by 15%. Why? The difficulty labels were skewed toward English patterns. A sentence that’s “complex” in English might be simple in another language. And then there’s the scale problem. OpenAI’s Noam Brown argues that once you hit trillion-parameter models, data quality and quantity matter more than order. Stanford’s Center for Research on Foundation Models agrees: curriculum helps up to 500B parameters. Beyond that, you need architectural changes too. Smaller teams struggle even more. A December 2025 survey by the AI Infrastructure Alliance found only 28% of companies with fewer than 50 ML engineers had successfully implemented curriculum learning. At big tech firms? It’s 76%. The gap isn’t just about money-it’s about data pipelines, annotation teams, and engineering bandwidth.What’s Happening Right Now (Early 2026)
The field is moving fast. In November 2025, Google released AutoCurriculum, a system that uses reinforcement learning to adjust data mixtures while the model trains. It didn’t need human-designed schedules-it learned them on its own. Result? A 9.3% boost on complex reasoning tasks. MIT-IBM dropped DataComp-2026 in early December: 10 trillion tokens, fully annotated across 12 dimensions. It’s open-source. You can download it today. And the market is catching up. The global AI data optimization tool market hit $2.8 billion in Q4 2025. AWS’s DataMixer service now leads the curriculum segment with 31% share. Startups like DataHarmonics raised $47 million to build tools that automate tagging and scheduling. But here’s the reality: there are 14 competing frameworks for curriculum learning. None has more than 22% adoption. That means if you pick one, you might be locked in. Interoperability is a mess.
Should You Use It?
If you’re training a model under 500B parameters and you have even a small data team, yes-start experimenting. Don’t build a monster system. Start with this:- Use DataComp-2026 as your base dataset.
- Sort your training data by sentence length and concept density (you can use Hugging Face’s
textstatlibrary for a quick proxy). - Train two models: one with random data, one with sorted data.
- Compare performance on MATH and GSM8K benchmarks.
The Bigger Picture
The industry is tired of chasing bigger models. They’re too expensive. Too energy-intensive. Too slow to train. Curriculum learning and smart data mixtures are the first real alternative. By 2027, analysts predict these techniques will deliver 25-30% of all performance gains in new LLMs. That means less compute, less carbon, and faster innovation. This isn’t about making models smarter. It’s about making training smarter. The next generation of LLMs won’t be the biggest. They’ll be the best-organized.What’s the difference between curriculum learning and data mixture in LLMs?
Curriculum learning refers to the order in which data is presented during training-starting simple and gradually increasing difficulty. Data mixture refers to the composition of the training dataset-what types of content (e.g., code, math, news, dialogue) are included and in what proportions. Together, they form a strategy: not just what you train on, but when and how often.
Can I implement curriculum learning without a big team?
Yes. Start with open-source tools like MIT-IBM’s DataComp-2026 dataset and sort your data by sentence length or complexity score using simple libraries like textstat. You don’t need to tag every document manually. Even a basic difficulty-based ordering can give you 5-8% gains on reasoning tasks.
Does curriculum learning work for multilingual models?
It can, but only if the difficulty labels are calibrated per language. Many systems are biased toward English syntax. For low-resource languages, you need language-specific complexity metrics. Tools like DataComp-2026 include multilingual annotations, but you still need to validate them on your target languages.
Is curriculum learning worth the extra training overhead?
Yes, if you’re training beyond 10B parameters. The 8-12% overhead in preprocessing is typically offset by 15-20% faster convergence. That means fewer GPU hours, lower costs, and quicker iteration cycles. For most teams, the net savings are positive.
How do I measure if my curriculum is working?
Compare your model’s performance on benchmarks like MATH, GSM8K, and HumanEval against a baseline trained with random data. Track loss curves over time-models with good curricula show steeper early drops. Also monitor performance per domain: if science accuracy jumps but basic grammar stays flat, your curriculum is doing its job.



Finally, someone gets it. Random data is garbage. I've seen models trained on 500B tokens still choke on basic logic because they never learned to build up from fundamentals. This isn't magic-it's pedagogy. The brain doesn't learn calculus before arithmetic, and neither should LLMs.
They’re hiding the real truth-this is just controlled data poisoning. Who decides what’s ‘simple’ or ‘complex’? It’s always the same elite labs writing the curriculum. Next they’ll tell us what words we’re allowed to learn. This isn’t progress-it’s cognitive gatekeeping disguised as science. They don’t want models to be free. They want them obedient.
Man I tried this with a 7B model last week using DataComp-2026 and just sorted by sentence length. Got a 6% bump on GSM8K with zero extra compute. No joke. I was skeptical too but wow. Even my dog could tell the answers made more sense now. Seriously, if you’re not doing this yet you’re leaving performance on the table.
omg i just read this and i’m so excited!! i tried the textstat thing on my little finetuning project and it actually worked?? like my model stopped saying ‘the sky is green’ and started making sense?? i didnt even know what curriculum learning was a week ago but now i’m obsessed!! thanks for sharing!!
Let’s be clear: this isn’t innovation-it’s a Band-Aid on a broken system. We’ve spent billions building models that require artificial scaffolding just to function. We should be asking why we’re training models like toddlers instead of designing architectures that learn like humans. This is engineering laziness dressed up as efficiency. The real breakthrough? Stop pretending data ordering can substitute for true understanding. We’re building smarter toddlers, not smarter minds.