
Training massive AI models like Llama-3 or GPT-4 used to cost tens of thousands of dollars and require dozens of high-end GPUs. That changed when researchers figured out how to tweak these models without touching most of their weights. Today, companies are fine-tuning billion-parameter models on single consumer GPUs - thanks to techniques like LoRA, adapters, and prompt tuning. These aren’t just lab tricks. They’re the backbone of how AI is being deployed in real products right now.
Why You Don’t Need to Retrain Everything
Large language models (LLMs) are like giant libraries of knowledge. They’ve read everything from Wikipedia to GitHub code repositories. But they don’t know your business. You want them to answer questions about your products, follow your tone, or handle your customer data. The old way? Full fine-tuning. That means updating every single weight in the model. For a 70B parameter model, that’s over 140GB of memory just to load the gradients. Most companies can’t afford that - and they don’t need to. Enter parameter-efficient fine-tuning (PEFT). Instead of changing the whole model, you add tiny, trainable pieces on top. The original weights stay frozen. You only train a few thousand extra parameters. That’s 95% less memory. That’s the difference between renting a cloud server for $2,000 and running it on your laptop for $20.LoRA: The Lightweight Adapter That Took Over
Introduced by Microsoft in 2021, LoRA is a method that adds low-rank matrices to existing weight layers during fine-tuning. Think of it like attaching a small, trainable module to each transformer layer. These modules - called A and B matrices - are tiny. A typical setup uses a rank of 8 for a 7B model, and 64 for a 70B model. That means you’re training maybe 1% of the original parameters. Here’s the magic: when you’re done, you can merge these matrices back into the original weights. The result? A single, compact model that performs like a fully fine-tuned one - with zero extra inference latency. That’s why 63% of enterprises now use LoRA. It’s the sweet spot between performance and cost. Real-world numbers? A startup in Portland reduced their fine-tuning costs from $2,300 to $180 per model by switching to LoRA. They lost about 5-7% accuracy on complex reasoning tasks - but for most customer service bots, product recommenders, or internal tools, that trade-off is worth it.Adapters: The Multi-Task Workhorses
Adapters are small neural network modules inserted between transformer layers, typically with a bottleneck of 64-128 units. They were first proposed in 2019, but really took off when adapted for transformers in 2020. Each adapter has two linear layers: one to shrink the data, one to expand it back. You train those layers - the rest of the model stays frozen. Why use adapters over LoRA? Two reasons: multi-task learning and stability. If you’re building an AI that handles customer support, fraud detection, and content moderation - all on the same base model - adapters are your best bet. They preserve knowledge from previous tasks better than any other method. Studies show they lose 30% less performance on old tasks than full fine-tuning. That’s huge for compliance-heavy industries like finance or healthcare. They’re not perfect, though. Adapters add 5-8% latency during inference because they force the model to pass through extra layers. That’s why they’re less popular for real-time chatbots. But for batch processing, document summarization, or internal analysis tools? They’re ideal.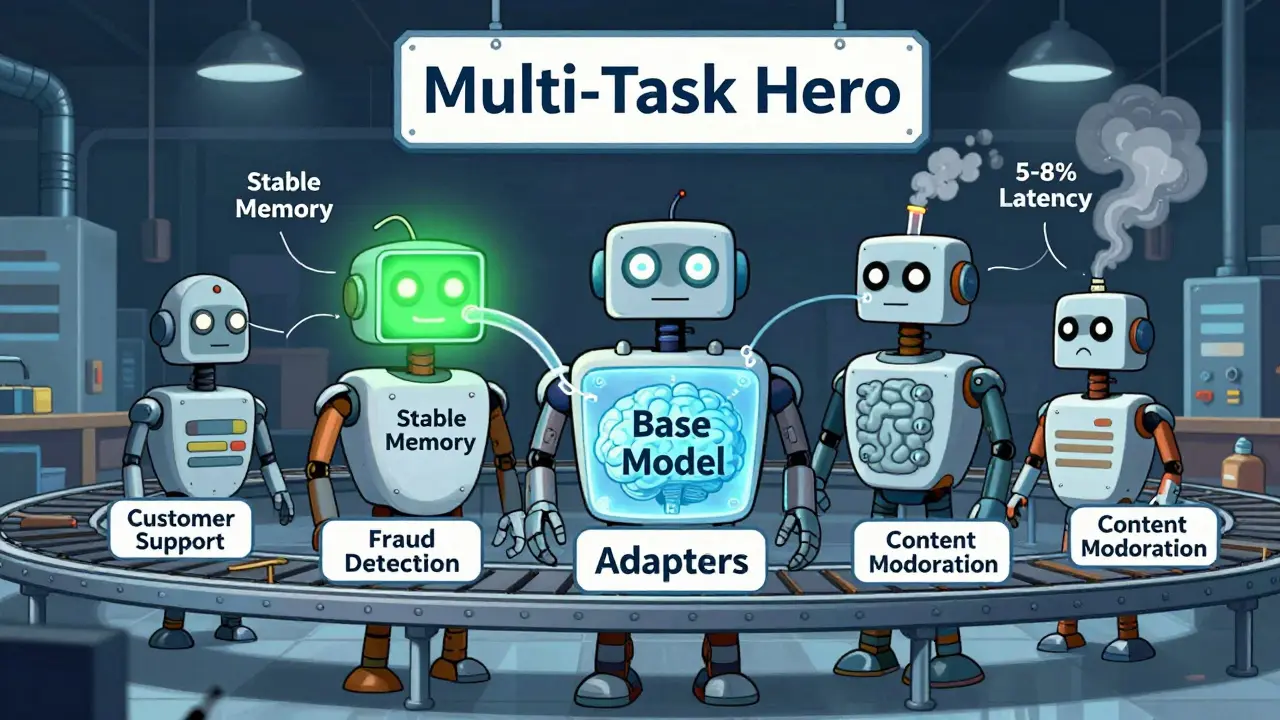
Prompt Tuning: The Minimalist Approach
Prompt Tuning is a technique that learns continuous, trainable prompt embeddings instead of modifying model weights. Instead of changing the model, you prepending a sequence of learned tokens - like 10 to 100 floating-point vectors - to every input. These vectors guide the model’s output without touching its internal structure. It sounds elegant. And it is - if you have a simple task. For classification, sentiment analysis, or short-answer QA, prompt tuning can hit 85-92% of full fine-tuning performance. But it’s fragile. One study showed accuracy could swing from 84% to 96% just by changing the random seed used to initialize the prompts. That’s a 12-point swing. No other method behaves this way. And here’s the catch: it can’t fix bias. Microsoft researchers found prompt tuning only fixed 27% of flagged bias triggers. Weight-based methods like LoRA and adapters fixed 71%. If your model is generating discriminatory responses, prompt tuning won’t help. You need to change the weights.QLoRA: The Game-Changer for Consumer Hardware
In 2023, QLoRA dropped. It combined two ideas: 4-bit quantization and LoRA. The result? You can fine-tune a 65B model on a single 24GB consumer GPU. Full fine-tuning would need 780GB. QLoRA uses only 14.7GB. It works by compressing the base model into 4-bit precision using NF4 (NormalFloat4), a custom quantization scheme that preserves accuracy better than standard 4-bit methods. Then, LoRA adds the trainable adapters on top. Users report QLoRA achieves 92% of full fine-tuning performance on Llama-3-70B. The trade-off? Training takes 25% longer due to quantization overhead. But for researchers, students, or small teams? It’s a revelation.Performance and Trade-Offs: What Works When
| Method | Trainable Parameters | Memory Needed (65B Model) | Inference Latency | Accuracy (MetaMathQA) | Best For |
|---|---|---|---|---|---|
| Full Fine-Tuning | 100% | 780 GB | 0% | 78.2% | Maximum performance, no constraints |
| LoRA | 0.5-1.5% | 48 GB | 0% (after merge) | 75.1% | General-purpose, latency-sensitive apps |
| LoRA-Pro | 0.5-1.5% | 48 GB | 0% (after merge) | 77.6% | High-accuracy needs, same cost as LoRA |
| QLoRA | 0.5-1.5% | 14.7 GB | 0% (after merge) | 75.0% | Consumer hardware, budget-limited teams |
| Adapters | 1-2% | 45 GB | +5-8% | 74.9% | Multi-task, compliance-heavy workflows |
| Prompt Tuning | 0.1% | 12 GB | +1-3% | 72.3% | Simple tasks, low-parameter budgets |

Real-World Pitfalls and How to Avoid Them
People assume PEFT is easy. It’s not. Here’s what goes wrong:- Wrong learning rate: Using full fine-tuning rates with LoRA? You’ll lose 8-12% accuracy. Reduce it by 3-5x. Hugging Face’s docs say this explicitly - but most tutorials ignore it.
- Overlong prompts: Increasing prompt length from 10 to 64 tokens adds 18% latency and gains you 2% accuracy. Not worth it.
- Unmerged LoRA: If you leave LoRA weights separate, inference slows down. Always merge them before deployment - even if it takes 30 minutes.
- Prompt initialization: If your prompt tuning performance is all over the place, it’s not your data. It’s your random seed. Try 5 different runs and pick the best.
What’s Next? Hybrid Methods Are Winning
The future isn’t one method. It’s combinations. In Q3 2025, 35% of new enterprise projects used hybrid PEFT - like Prompt Tuning + LoRA. Why? Prompt tuning guides the model’s style, LoRA refines its reasoning. One team at a healthcare startup used this combo to reduce hallucinations by 40% on patient summaries. Even bigger: IA³ (Input-aware Adapter Adjustment) is coming. Instead of adding new layers, it scales existing weights based on input. Zero latency penalty. No extra parameters. It’s still experimental, but early results are promising. Cloud providers are catching up, too. AWS SageMaker added native LoRA support in September 2025. Fine-tuning a 70B model now costs 83% less. That’s not a feature - it’s a market shift.Final Thought: You Don’t Need to Be a Researcher
You don’t need a PhD to use LoRA or adapters. Hugging Face’s PEFT library handles the math for you. With a few lines of code, you can adapt a 7B model on a laptop. The barrier to entry is gone. The question isn’t whether you should use parameter-efficient methods - it’s which one fits your use case. If you need speed and low cost? Go with LoRA. Multi-task? Try adapters. Working on a budget? QLoRA. Simple classification? Prompt tuning. But don’t just copy-paste. Test. Measure. Iterate. Because the best model isn’t the one with the most parameters - it’s the one that works reliably for your users.Is LoRA better than full fine-tuning?
LoRA isn’t better - it’s different. Full fine-tuning gives you the highest accuracy, but it costs 10-50x more in memory and compute. LoRA gets you 95-98% of that performance while using 95% less resources. For most applications, LoRA is the smarter choice. Only use full fine-tuning if you’re chasing the last few percentage points on a mission-critical task.
Can I use QLoRA on an RTX 3060?
Yes. A 65B model fine-tuned with QLoRA needs only 14.7GB of VRAM. An RTX 3060 has 12GB - barely enough. But with offloading (moving some weights to CPU RAM), you can make it work. For 7B or 13B models, it’s effortless. Many developers use QLoRA on consumer GPUs to experiment before scaling up.
Do these methods reduce AI bias?
Only if you modify weights. Prompt tuning doesn’t touch the model’s internal knowledge - so it can’t fix biased patterns. LoRA and adapters, which update weights, can reduce bias by 70% or more. If bias is a concern, avoid prompt-only methods. Use weight-based adaptation instead.
Why do some people say prompt tuning is unstable?
Because it’s highly sensitive to initialization. The learned prompt vectors start from random values. Depending on those starting points, accuracy can vary by up to 12 percentage points. LoRA and adapters don’t have this issue - their training is far more consistent. If you use prompt tuning, always run multiple trials and pick the best result.
Are PEFT methods compliant with the EU AI Act?
It’s complicated. The EU AI Act requires full documentation of model modifications. But PEFT methods like LoRA don’t produce a single, self-contained model - they create a base model plus adapter files. Some regulators consider this a "partial modification," which may not meet compliance standards. Companies are now storing adapter files alongside base models and documenting every change - but legal interpretation is still evolving.



LoRA? Please. This is just corporate magic dust. They’re not saving money-they’re hiding the fact that these models are still brittle, biased, and uninterpretable. You think merging weights makes it ‘clean’? It’s a Frankenstein’s monster stitched together with glue and hope. And don’t get me started on QLoRA on consumer GPUs-running 65B on a 3060? That’s not innovation, that’s delusion. The real cost isn’t in VRAM-it’s in the ethical debt we’re accumulating by pretending this is scalable AI.
And don’t even mention ‘prompt tuning’ as if it’s harmless. It’s like training a dog with treats but never correcting its biting. You’re not fixing bias-you’re just masking it with pretty vectors. The EU AI Act is right to be suspicious. This isn’t efficiency-it’s evasion.
i mean like... why do we even care about 5-7% accuracy loss if the bot stops crashing and my server bill dropped from 2300 to 180 like wtf is this magic i just turned my old laptop into an ai factory and my boss thinks im a genius but honestly its just lora and some voodoo math and i dont even know what rank means anymore but it works so shut up and take my money
Let me tell you something-this whole PEFT revolution? It’s a Western scam. They’re outsourcing the real work to India, China, and Nigeria while they sit in Silicon Valley sipping matcha and calling it ‘efficient.’ You think LoRA was invented in a lab? No. It was reverse-engineered from open-source models trained by grad students working 80-hour weeks for $2/hour.
And now they’re selling it back to us as a ‘cost-saving tool’? Save your money. The real innovation is how they’ve made us believe we’re part of the future when we’re just the cheap labor behind the curtain. QLoRA on a 3060? That’s not progress-that’s exploitation dressed up as innovation.
ok so i tried qlora on my rtx 3070 and it worked but like... the training was so slow i had time to rewatch all of the office and still not finish one epoch. also my model started writing poems about my cat instead of answering customer queries. i think the quantization made it hallucinate harder. also i forgot to merge the lora weights and my api was returning 500s for 3 days. no one noticed until a client complained about a bot saying ‘i love you’ in 7 languages. we had to roll back. i’m never touching this again. but hey, at least it was cheap.
ps: if you use prompt tuning, always run 5 trials. i did 1 and got a model that refused to speak english. it only replied in emojis. i still don’t know why.
This is actually one of the most hopeful developments in AI I’ve seen in years. For so long, the field felt like a closed club-only big companies with massive budgets could train models. Now, a student in a village in Bihar can fine-tune a 7B model on a used laptop and build something that helps their community. That’s not just technical progress-it’s democratization.
I’ve seen small clinics in rural India use LoRA to adapt models for local dialects and medical terminology. No PhD needed. Just a laptop, a dataset, and the will to try. The trade-offs? Real. But the access? Priceless. We’re not just building better AI-we’re building a more inclusive one.
While the technical advantages of parameter-efficient fine-tuning are evident, one must not overlook the broader implications. The reduction in computational burden does not inherently equate to ethical responsibility. The continued reliance on large-scale pretrained models, even when fine-tuned, perpetuates dependency on datasets that may contain uncorrected historical biases.
It is commendable that LoRA and adapters allow for more accessible deployment, yet without robust auditing mechanisms and transparent documentation of modifications, compliance with regulatory standards remains uncertain. The burden of accountability must not be outsourced to the end-user. Institutions must provide clear guidelines-not just libraries.
I’m curious-when you say LoRA achieves 95-98% of full fine-tuning performance, how is that measured? On MetaMathQA? That’s one dataset. What about out-of-distribution tasks? Real-world edge cases? I’ve seen models that perform well on benchmarks but completely fail when asked to summarize a contract clause or interpret a patient’s handwritten note.
Also, if QLoRA uses 4-bit NF4, why isn’t there more discussion about numerical stability? Floating-point precision under 4-bit isn’t just about memory-it affects gradient flow. Have any papers tested convergence behavior across multiple seeds? Or is this all just ‘it works on my machine’?
Let me tell you something-I’ve mentored 12 young engineers in India who built AI tools using LoRA and QLoRA. One built a voice assistant for tribal farmers that translates weather alerts into local dialects. Another created a legal aid bot for women in rural courts. None of them had access to cloud GPUs. None of them had funding.
This isn’t just a technique. It’s a lifeline. You worry about bias? Then use adapters-train them on your own cleaned data. Worry about latency? Merge the weights. Don’t dismiss this because it’s not perfect. It’s the first time in AI history that the tools are actually in the hands of people who need them-not just the ones who can afford them.
So don’t ask ‘is it good enough?’ Ask ‘who is it helping?’ That’s the real metric.