
You have a dataset full of customer chats. You want to feed it into your Large Language Model workflow to build a better support bot. But there is a catch. That data contains names, emails, and maybe even medical records or financial details. If you just dump that raw data into your model training pipeline, you are risking massive fines under the General Data Protection Regulation (GDPR) and losing your users' trust.
The solution lies in two specific techniques: Anonymization and Pseudonymization. They sound similar, but they are not interchangeable. Choosing the wrong one can break your application logic or expose you to legal liability. Let’s look at exactly how these methods work, where they fail, and which one fits your specific engineering needs.
The Core Difference: Reversibility and Legal Status
The biggest difference between these two approaches is simple: can you get the original data back?
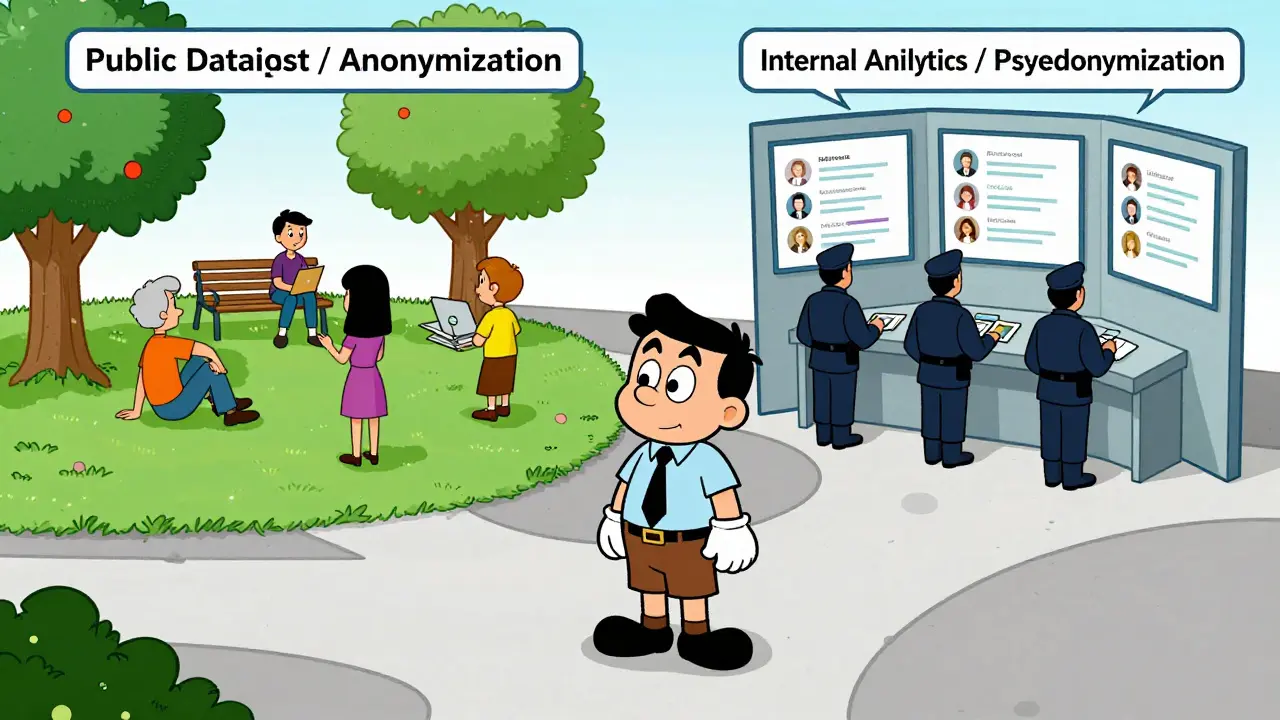
Anonymization is permanent. Once you anonymize data, you cannot reverse it. There is no key, no secret file, and no process to re-identify the person behind the data. Because it is irreversible, properly anonymized data falls outside the scope of GDPR. It is no longer considered personal data. If this data leaks, you generally do not need to notify regulators because no individual can be identified from it.
Pseudonymization, on the other hand, is reversible. You replace sensitive identifiers with artificial values-like turning "John Doe" into "USER_123". However, you keep a separate mapping table or encryption key that links "USER_123" back to "John Doe". Under GDPR, pseudonymized data is still treated as personal information. If the mapping key is stolen along with the data, or if an attacker figures out the pattern, you are liable. Breaches involving pseudonymized data trigger mandatory notification requirements.
| Feature | Anonymization | Pseudonymization |
|---|---|---|
| Reversibility | Irreversible (One-way) | Reversible (With Key) |
| GDPR Status | Not Personal Data | Personal Data |
| Data Utility | Lower (Loss of context) | High (Retains relationships) |
| Breach Risk | Low (No ID recovery) | Medium/High (If key compromised) |
| Best Use Case | Public datasets, Third-party sharing | Internal analytics, Customer service |
Implementing Anonymization in LLM Pipelines
When you choose anonymization, you are betting on total separation. The goal is to strip every trace of identity while keeping the text useful for training. This is harder than it sounds because Large Language Models rely heavily on context.
Common techniques include:
- Data Masking: Replacing sensitive fields with fictional but realistic values. For example, using the Faker Python library to generate fake names like "Alice Smith" instead of real ones. This keeps the data structure intact so the model learns patterns without memorizing real identities.
- Generalization: Reducing precision. Instead of storing a user's age as "34", you store it as "30-40". This removes unique identifiers but preserves demographic trends useful for broad analysis.
- Tokenization: Replacing sensitive words with unique tokens that have no semantic meaning. "New York" becomes "LOC_99". Unlike pseudonymization, these tokens should not map back to anything.
A major challenge here is utility loss. If you mask too much, the model doesn't learn well. Research published in the ACL Anthology PrivateNLP workshop in 2025 tested three strategies: simple masking, contextual anonymization (adding descriptions to masked entities), and pseudonymization. They found that while all methods preserved 97%-99% of entity privacy, response quality dropped by about 1 point on a 10-point scale.
Interestingly, the results varied by model architecture. For Llama 3.3:70b, simple anonymization worked best (scoring 0.83 in inference). Adding context actually hurt performance (dropping to 0.46) because the model tried to reconstruct the original entities from the hints. However, for GPT-4o, adding context improved response quality. This means you must test your specific model to see how it handles stripped data.

Implementing Pseudonymization for Contextual Integrity
Pseudonymization is often preferred in business workflows where you need to track a user over time. Think about customer support. If a user complains on Monday and calls back on Wednesday, you need the system to know it is the same person to provide consistent help. Anonymization breaks this link; pseudonymization maintains it securely.
Technical implementation usually involves Named Entity Recognition (NER). Modern pipelines use transformer models like XLM-RoBERTa-large-finetuned-conll03-english to identify entities. The system scans text, finds "John Doe" and "New York", and replaces them with structured pseudonyms like "PERSON_1" and "LOCATION_1". Crucially, the same person always gets the same pseudonym within a session or dataset, preserving relational integrity.
This approach offers high data utility. The model sees consistent references, allowing it to learn complex relationships between entities. However, it demands strict security controls. You must manage the mapping keys separately from the data. Access to these keys requires robust authentication and audit trails. If an attacker gains access to both the pseudonymized dataset and the key, they can re-identify individuals, triggering GDPR breach notifications.
Security Risks and Inference Attacks
Even with pseudonymization, you are not completely safe. Large Language Models are powerful pattern recognizers. They can sometimes infer identities from context, even when direct identifiers are removed. This is known as an inference attack.
Recent studies show that pseudonymization is effective against many inference attacks, but not all. The risk depends on the task type and the model's capabilities. For instance, if you only remove direct identifiers (names, emails) but leave indirect identifiers (job title, rare hobbies, location), a sophisticated model might piece together the identity. Training models on datasets with only indirect identifiers removed provides less privacy protection than removing direct identifiers first.
To mitigate this, consider combining techniques. Use pseudonymization for direct identifiers to maintain utility, and apply generalization or suppression to indirect identifiers that could lead to re-identification. Always evaluate your pipeline against potential inference vectors specific to your domain.
Choosing the Right Strategy for Your Workflow
There is no universal winner. Your choice depends on your business goals and regulatory constraints.
Choose Pseudonymization if:
- You need to link user interactions across multiple sessions (e.g., customer service history).
- You share data with trusted partners who need to analyze trends but not identities.
- You operate in healthcare or finance where longitudinal tracking is essential for treatment or fraud prevention.
- You have strong security infrastructure to protect encryption keys and access logs.
Choose Anonymization if:
- You plan to publish the dataset publicly or share it with untrusted third parties.
- Your primary goal is strict GDPR compliance and minimizing breach liability.
- You do not need to track individual users over time.
- You are building public benchmarks or open-source models where privacy is paramount.
In practice, many organizations use a hybrid approach. They pseudonymize data for internal development and testing, then apply rigorous anonymization before releasing any derived insights or models to the public. This balances utility during development with safety in deployment.
Is pseudonymized data safe from GDPR penalties?
No. Pseudonymized data is still considered personal data under GDPR. If a breach occurs and the mapping key is compromised, you must notify authorities. Anonymized data, if truly irreversible, is exempt from GDPR regulations.
Which technique reduces LLM response quality more?
Both cause minimal loss, typically around 1 point on a 10-point scale. However, simple anonymization may perform better on some models like Llama 3.3, while contextual pseudonymization might help others like GPT-4o. Testing your specific model is crucial.
Can I convert pseudonymized data to anonymized data later?
Yes, but you must destroy the mapping keys permanently. Once the keys are gone, the data becomes anonymized. Ensure this destruction is verifiable and documented for compliance audits.
What tools are best for implementing these techniques?
For anonymization, libraries like Faker (Python) are standard for generating fake data. For pseudonymization, NER models like XLM-RoBERTa combined with custom tokenization scripts are effective. Specialized privacy platforms also offer pre-built pipelines for GDPR compliance.
Does removing names guarantee privacy in LLMs?
No. LLMs can infer identities from indirect identifiers like job titles, locations, or unique experiences. You must also generalize or suppress indirect identifiers to prevent re-identification through inference attacks.



I have been wrestling with this exact dilemma for our internal customer support bot. The distinction between the two is often blurred in marketing materials, but your breakdown of the reversibility aspect is spot on. We initially tried full anonymization using a simple masking library, but the model performance tanked because it couldn't maintain context across multi-turn conversations. Switching to pseudonymization allowed us to keep the relational integrity while still protecting PII, provided we secured the mapping keys properly.
Oh, please. This is such a superficial take on data privacy engineering. You are ignoring the nuanced reality of semantic leakage in transformer architectures. It is not just about 'keys' and 'tables'. One must consider the epistemic vulnerability of the latent space representations themselves. Most practitioners here are woefully underqualified to handle the inferential risks of high-dimensional vector embeddings without implementing differential privacy mechanisms alongside their NER pipelines. Your reliance on standard GDPR definitions shows a lack of deep theoretical understanding of modern adversarial machine learning frameworks.
It is imperative that organizations prioritize the security infrastructure required for pseudonymization before attempting implementation. The article correctly identifies that the mapping key is the critical vulnerability. In my experience managing enterprise data lakes, the failure point is rarely the algorithm itself, but rather the access control lists governing the key management service. I recommend implementing hardware security modules for key storage and enforcing strict audit trails for every decryption event. Without these rigorous controls, pseudonymization offers a false sense of security that can lead to catastrophic compliance failures.
Good summary. Keep it simple.
We are merely shadows dancing on the wall of the cave, pretending that stripping names from text will liberate us from the chains of identity. Is a person truly anonymous if their soul's unique fingerprint remains in the syntax? The LLM does not just read words; it consumes the essence of human interaction. When we pseudonymize, we create a ghost that still haunts the server. When we anonymize, we kill the ghost entirely. Which is more ethical? To let the ghost live in exile, or to bury it so deep it never rises? The code does not care. Only the philosopher does. And yet, we write the code anyway.
The grammatical structure of the section regarding inference attacks is somewhat lacking in precision. Specifically, the phrase 'they can sometimes infer identities' should be rephrased to 'models may occasionally deduce identities' to avoid anthropomorphizing the algorithmic process. Furthermore, the use of contractions throughout the text undermines the formal tone necessary for technical documentation. While the content is informative, the presentation suffers from inconsistent punctuation and overly casual phrasing which detracts from the authority of the argument. Please revise for clarity and adherence to standard English conventions.